










2016 թվականին, ելույթ ունենալով Դավոսի Համաշխարհային տնտեսական ֆորումում, նրա նախագահ Կլաուս Մարտին Շվաբը խոսեց «Չորրորդ արդյունաբերական հեղափոխության» մասին՝ ամբողջական ավտոմատացման նոր դարաշրջանի, որը մրցակցություն է ստեղծում մարդկային բանականության և արհեստական բանականության միջև: Այս ելույթը (ինչպես նաև համանուն գիրքը) համարվում է շրջադարձային նոր տեխնոլոգիաների զարգացման գործում։ Շատ երկրներ ստիպված են եղել ընտրել, թե որ ճանապարհն են գնալու՝ տեխնոլոգիայի առաջնահերթությունը անհատական իրավունքների և ազատությունների նկատմամբ, թե՞ հակառակը։ Այսպիսով, տեխնոլոգիական շրջադարձը վերածվեց սոցիալական և քաղաքական շրջադարձի։
Էլ ինչի՞ մասին խոսեց Շվաբը, և ինչո՞ւ է դա այդքան կարևոր:
Հեղափոխությունը կփոխի մարդկանց և մեքենաների միջև ուժերի հարաբերակցությունը՝ արհեստական ինտելեկտը (AI) և ռոբոտները կստեղծեն նոր մասնագիտություններ, բայց նաև կսպանեն հիններին։ Այս ամենը հասարակության մեջ սոցիալական անհավասարության և այլ ցնցումների տեղիք կտա։
Թվային տեխնոլոգիաները հսկայական առավելություն կտան նրանց, ովքեր ժամանակին խաղադրույք կկատարեն դրանց վրա՝ գյուտարարներին, բաժնետերերին և վենչուրային ներդրողներին: Նույնը վերաբերում է պետություններին։
Այսօր գլոբալ առաջնորդության համար մրցավազքում հաղթում է ով արհեստական ինտելեկտի ոլորտում ամենամեծ ազդեցությունն ունի: Առաջիկա հինգ տարում AI տեխնոլոգիաների կիրառումից համաշխարհային շահույթը գնահատվում է 16 տրլն դոլար, իսկ բ.Ամենամեծ մասնաբաժինը բաժին կհասնի ԱՄՆ-ին և Չինաստանին։
Չինացի ՏՏ փորձագետ Կայ-Ֆու Լին իր «Արհեստական ինտելեկտի գերհզորությունները» գրքում գրում է տեխնոլոգիայի ոլորտում Չինաստանի և ԱՄՆ-ի պայքարի, Սիլիկոնային հովտի ֆենոմենի և երկու երկրների միջև հսկայական տարբերության մասին:
ԱՄՆ և Չինաստան. սպառազինությունների մրցավազք
USA համարվում է արհեստական ինտելեկտի ոլորտում ամենազարգացած երկրներից մեկը։ Սիլիկոնյան հովտում տեղակայված համաշխարհային հսկաները, ինչպիսիք են Google-ը, Apple-ը, Facebook-ը կամ Microsoft-ը, մեծ ուշադրություն են դարձնում այս զարգացումներին: Նրանց միանում են տասնյակ ստարտափներ։
2019 թվականին Դոնալդ Թրամփը հանձնարարել է ստեղծել ամերիկյան AI նախաձեռնություն։ Այն աշխատում է հինգ ոլորտներում.
Պաշտպանության դեպարտամենտի արհեստական ինտելեկտի ռազմավարությունը խոսում է այդ տեխնոլոգիաների օգտագործման մասին՝ ռազմական կարիքների և կիբերանվտանգության համար: Միևնույն ժամանակ, դեռ 2019 թվականին Միացյալ Նահանգները ճանաչեց Չինաստանի գերակայությունը արհեստական ինտելեկտի հետազոտությունների հետ կապված որոշ ցուցանիշներով։
2019 թվականին ԱՄՆ կառավարությունը մոտ 1 միլիարդ դոլար է հատկացրել արհեստական ինտելեկտի ոլորտում հետազոտությունների համար։ Այնուամենայնիվ, մինչև 2020 թվականը ԱՄՆ գործադիր տնօրենների միայն 4%-ն է նախատեսում ներդնել AI տեխնոլոգիա՝ 20-ի 2019%-ի դիմաց: Նրանք կարծում են, որ տեխնոլոգիայի հնարավոր ռիսկերը շատ ավելի բարձր են, քան դրա հնարավորությունները:
ճենապակի նպատակ ունի առաջ անցնել ԱՄՆ-ից արհեստական ինտելեկտով և այլ տեխնոլոգիաներով։ Ելակետ կարելի է համարել 2017 թվականը, երբ հայտնվեց AI տեխնոլոգիաների զարգացման ազգային ռազմավարությունը։ Ըստ այդմ՝ մինչև 2020 թվականը Չինաստանը պետք է հասներ այս ոլորտում համաշխարհային առաջատարների հետ, իսկ արհեստական ինտելեկտի ընդհանուր շուկան երկրում պետք է գերազանցեր 22 միլիարդ դոլարը։ Նրանք նախատեսում են 700 միլիարդ դոլար ներդնել խելացի արտադրության, բժշկության, քաղաքների, գյուղատնտեսության և պաշտպանության ոլորտներում:
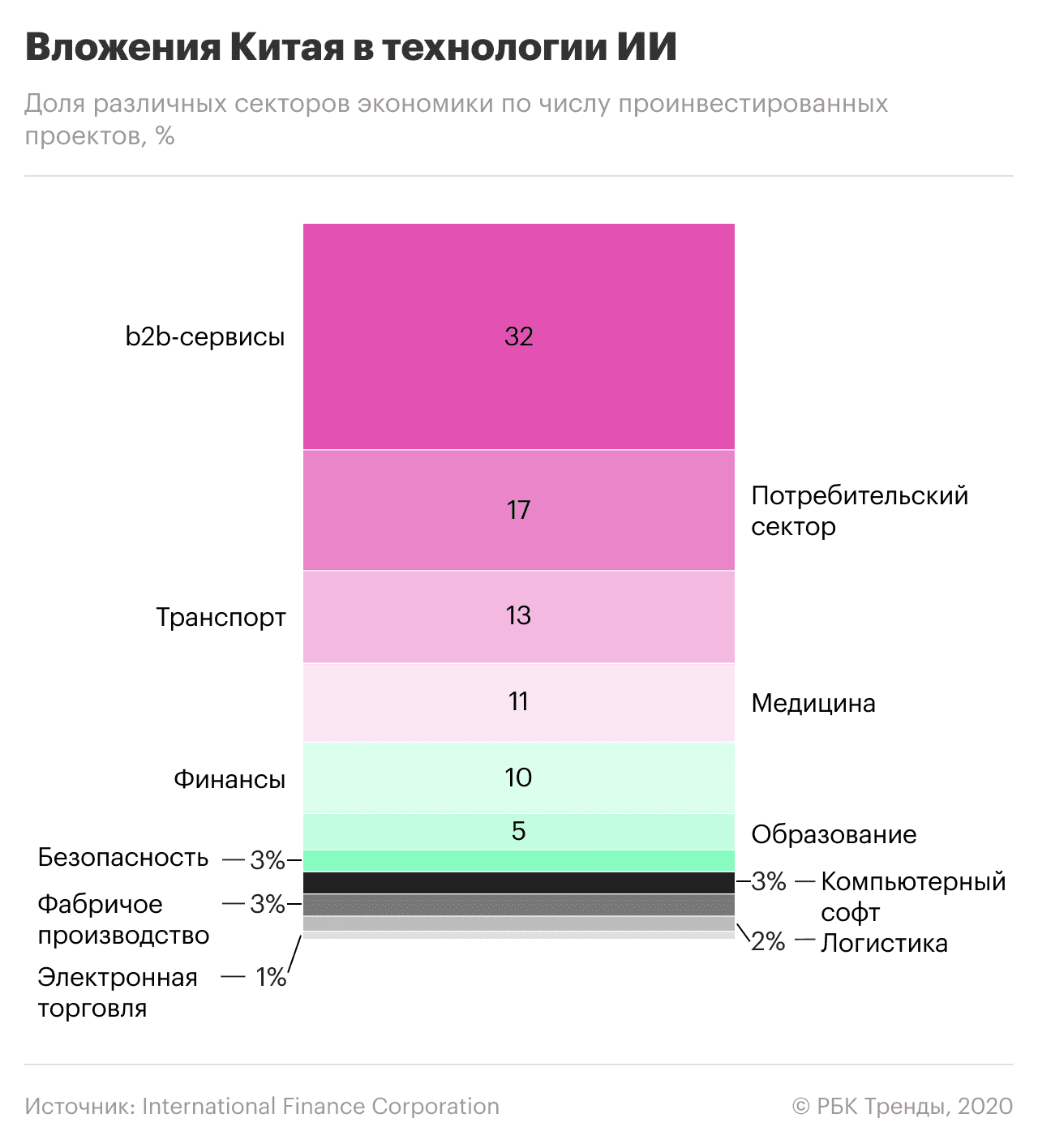
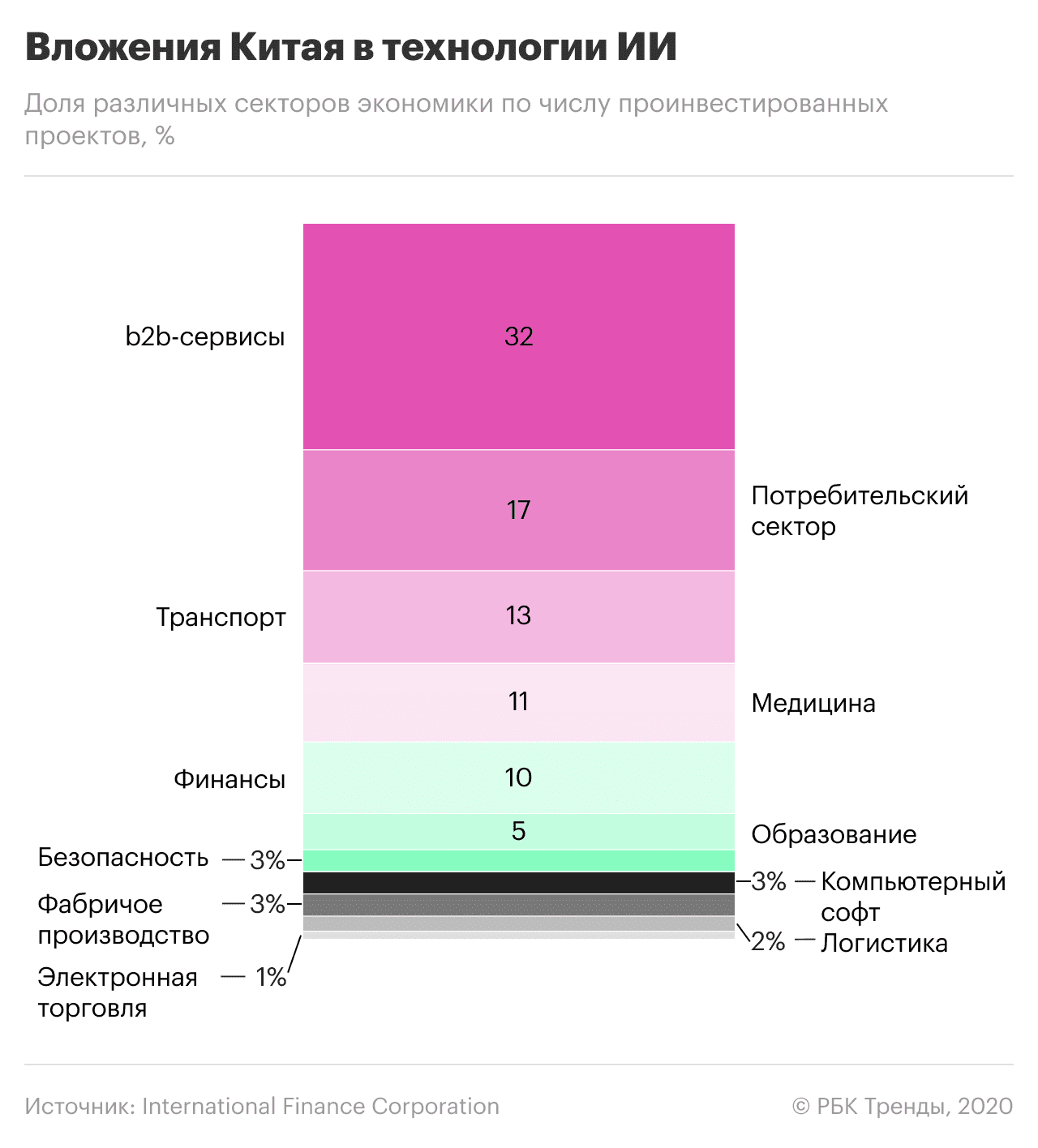
Չինաստանի առաջնորդ Սի Ցզինպինը AI-ն համարում է «տեխնոլոգիական հեղափոխության և տնտեսական աճի շարժիչ ուժը»: Չինական Google-ի նախկին նախագահ Լի Կայֆուն դա բացատրում է նրանով, որ AlphaGo-ն (Google-ի գլխավոր գրասենյակի զարգացումը) հաղթել է չինացի go game-ի չեմպիոն Կե Ջիեին։ Սա Չինաստանի համար տեխնոլոգիական մարտահրավեր է դարձել։
Հիմնական բանը, որով երկիրը մինչ այժմ զիջում է ԱՄՆ-ին և մյուս առաջնորդներին, հիմնարար տեսական հետազոտությունն է, AI-ի վրա հիմնված հիմնական ալգորիթմների և չիպերի մշակումը։ Դա հաղթահարելու համար Չինաստանն ակտիվորեն փոխառում է լավագույն տեխնոլոգիաներն ու մասնագետները համաշխարհային շուկայից՝ միաժամանակ թույլ չտալով արտասահմանյան ընկերություններին մրցակցել չինականների հետ ներքին շուկայում։
Միևնույն ժամանակ, արհեստական ինտելեկտի ոլորտի բոլոր ընկերություններից մի քանի փուլով ընտրվում են լավագույնները և բարձրացվում են ոլորտի առաջատարներին։ Նմանատիպ մոտեցում արդեն կիրառվել է հեռահաղորդակցության ոլորտում։ 2019 թվականին Շանհայում սկսեց կառուցվել նորարարության և արհեստական ինտելեկտի կիրառման առաջին փորձնական գոտին։
2020 թվականին կառավարությունը խոստանում է ևս 1,4 տրիլիոն դոլար 5G, AI և ինքնակառավարվող մեքենաների համար։ Նրանք խաղադրույքներ են կատարում ամպային հաշվարկների և տվյալների վերլուծության խոշորագույն մատակարարների վրա՝ Alibaba Group Holding-ի և Tencent Holdings-ի վրա:
Baidu-ն՝ «չինական Google»-ը՝ դեմքի ճանաչման մինչև 99% ճշգրտությամբ, iFlytek և Face ստարտափները եղել են ամենահաջողակները: Չինական միկրոսխեմաների շուկան միայն մեկ տարվա ընթացքում՝ 2018-ից 2019 թվականներին, աճել է 50%-ով՝ հասնելով 1,73 միլիարդ դոլարի:
Առևտրային պատերազմի և Միացյալ Նահանգների հետ դիվանագիտական հարաբերությունների վատթարացման պայմաններում Չինաստանն ակտիվացրել է արհեստական ինտելեկտի ոլորտում քաղաքացիական և ռազմական նախագծերի ինտեգրումը: Գլխավոր նպատակը ոչ միայն տեխնոլոգիական, այլեւ աշխարհաքաղաքական գերակայությունն է ԱՄՆ-ի նկատմամբ։
Չնայած Չինաստանին հաջողվել է առաջ անցնել ԱՄՆ-ից մեծ և անձնական տվյալների անսահմանափակ հասանելիության առումով, այն դեռ հետ է մնում տեխնոլոգիական լուծումների, հետազոտությունների և սարքավորումների ոլորտում։ Միևնույն ժամանակ, չինացիները AI-ի վերաբերյալ ավելի շատ մեջբերված հոդվածներ են հրապարակում։
Բայց արհեստական ինտելեկտի նախագծերը զարգացնելու համար մեզ անհրաժեշտ են ոչ միայն ռեսուրսներ և պետական աջակցություն։ Անհրաժեշտ է անսահմանափակ մուտք դեպի մեծ տվյալներ. հենց նրանք են հիմք տալիս հետազոտության և զարգացման, ինչպես նաև ռոբոտների, ալգորիթմների և նեյրոնային ցանցերի ուսուցման համար:
Մեծ տվյալներ և քաղաքացիական ազատություններ. ո՞րն է առաջընթացի գինը:
Մեծ տվյալներին ԱՄՆ-ում նույնպես լուրջ են վերաբերվում և հավատում են նրա տնտեսական զարգացման ներուժին: Նույնիսկ Օբամայի օրոք կառավարությունը գործարկեց 200 դաշնային մեծ տվյալների ծրագիր՝ ընդհանուր XNUMX միլիոն դոլարի չափով:
Այնուամենայնիվ, մեծ և անձնական տվյալների պաշտպանության դեպքում այստեղ ամեն ինչ այնքան էլ պարզ չէ: Բեկումնային պահը 11 թվականի սեպտեմբերի 2011-ի իրադարձություններն էին: Ենթադրվում է, որ հենց այդ ժամանակ պետությունը հատուկ ծառայություններին տրամադրել է իր քաղաքացիների անձնական տվյալների անսահմանափակ հասանելիություն:
2007 թվականին ընդունվել է «Ահաբեկչության դեմ պայքարի մասին» օրենքը։ Եվ նույն թվականից PRISM-ը հայտնվեց ՀԴԲ-ի և ԿՀՎ-ի տրամադրության տակ՝ ամենաառաջադեմ ծառայություններից մեկը, որը հավաքում է անձնական տվյալներ սոցիալական ցանցերի բոլոր օգտատերերի, ինչպես նաև Microsoft-ի, Google-ի, Apple-ի, Yahoo-ի և նույնիսկ հեռախոսի մասին: գրառումներ. Հենց այս բազայի մասին է խոսել Էդվարդ Սնոուդենը, ով նախկինում աշխատել է նախագծի թիմում։
Բացի չաթերում, էլ. նամակներում խոսակցություններից և հաղորդագրություններից, ծրագիրը հավաքում և պահպանում է աշխարհագրական տվյալներ, բրաուզերի պատմություն: Նման տվյալները ԱՄՆ-ում շատ ավելի քիչ պաշտպանված են, քան անձնական տվյալները։ Այս բոլոր տվյալները հավաքում և օգտագործում են նույն ՏՏ հսկաները Սիլիկոնյան հովտից:
Միևնույն ժամանակ, դեռևս գոյություն չունի մեծ տվյալների օգտագործումը կարգավորող օրենքների և միջոցառումների միասնական փաթեթ։ Ամեն ինչ հիմնված է յուրաքանչյուր կոնկրետ ընկերության գաղտնիության քաղաքականության և տվյալների պաշտպանության և օգտատերերին անանուն դարձնելու պաշտոնական պարտավորությունների վրա: Բացի այդ, յուրաքանչյուր պետություն ունի իր կանոններն ու օրենքներն այս առումով:
Որոշ նահանգներ դեռ փորձում են պաշտպանել իրենց քաղաքացիների տվյալները, գոնե կորպորացիաներից։ Կալիֆոռնիայում 2020 թվականից ի վեր տվյալների պաշտպանության ամենախիստ օրենքն ունի երկրում: Համաձայն դրա՝ համացանցի օգտատերերն իրավունք ունեն իմանալու, թե ընկերությունները ինչ տեղեկատվություն են հավաքում իրենց մասին, ինչպես և ինչու են այն օգտագործում: Ցանկացած օգտվող կարող է պահանջել, որ այն հեռացվի կամ արգելվի հավաքածուն: Մեկ տարի առաջ այն նաև արգելեց դեմքի ճանաչման կիրառումը ոստիկանության և հատուկ ծառայությունների աշխատանքում։
Տվյալների անանունացումը հանրաճանաչ գործիք է, որն օգտագործվում է ամերիկյան ընկերությունների կողմից. երբ տվյալները անանունացված են, և դրանցից անհնար է բացահայտել կոնկրետ անձին: Այնուամենայնիվ, սա ընկերությունների համար մեծ հնարավորություններ է բացում առևտրային նպատակներով տվյալներ հավաքելու, վերլուծելու և կիրառելու համար: Միևնույն ժամանակ, նրանց նկատմամբ այլևս չեն կիրառվում գաղտնիության պահանջները։ Նման տվյալներն ազատորեն վաճառվում են հատուկ բորսաների և անհատ բրոքերների միջոցով:
Դաշնային մակարդակով տվյալների հավաքագրումից և վաճառքից պաշտպանվելու համար օրենքներ առաջ քաշելով՝ Ամերիկան կարող է հանդիպել տեխնիկական խնդիրների, որոնք, փաստորեն, ազդում են բոլորիս վրա: Այսպիսով, դուք կարող եք անջատել տեղադրության հետագծումը ձեր հեռախոսում և հավելվածներում, իսկ ի՞նչ կասեք արբանյակների մասին, որոնք հեռարձակում են այս տվյալները: Այժմ դրանք շուրջ 800-ն են ուղեծրում, և անհնար է դրանք անջատել. այս կերպ մենք կմնանք առանց ինտերնետի, կապի և կարևոր տվյալների, այդ թվում՝ մոտալուտ փոթորիկների և փոթորիկների պատկերների:
Չինաստանում Կիբերանվտանգության մասին օրենքը գործում է 2017 թվականից: Այն, մի կողմից, արգելում է ինտերնետ ընկերություններին հավաքել և վաճառել տեղեկատվություն իրենց համաձայնությամբ օգտվողների մասին: 2018 թվականին նրանք նույնիսկ հրապարակեցին անձնական տվյալների պաշտպանության հստակեցում, որը համարվում է եվրոպական GDPR-ին ամենամոտներից մեկը։ Այնուամենայնիվ, հստակեցումը ընդամենը կանոնների ամբողջություն է, ոչ թե օրենք, և թույլ չի տալիս քաղաքացիներին պաշտպանել իրենց իրավունքները դատարանում:
Մյուս կողմից, օրենքը պահանջում է բջջային օպերատորներից, ինտերնետ ծառայություններ մատուցողներից և ռազմավարական ձեռնարկություններից տվյալների մի մասը պահել երկրի ներսում և պահանջի դեպքում փոխանցել իշխանություններին: Նման մի բան մեզ մոտ սահմանում է այսպես կոչված «Գարնանային օրենքը»։ Միևնույն ժամանակ, վերահսկող մարմիններին հասանելի է ցանկացած անձնական տեղեկատվություն՝ զանգեր, նամակներ, չաթեր, բրաուզերի պատմություն, աշխարհագրական դիրք:
Ընդհանուր առմամբ, Չինաստանում ավելի քան 200 օրենք և կանոնակարգ կա անձնական տեղեկատվության պաշտպանության վերաբերյալ: 2019 թվականից ի վեր բոլոր հայտնի սմարթֆոնների հավելվածները ստուգվում և արգելափակվում են, եթե դրանք հավաքում են օգտատերերի տվյալները օրենքի խախտմամբ։ Այն ծառայությունները, որոնք ստեղծում են գրառումների հոսք կամ ցուցադրում են գովազդ՝ հիմնված օգտատերերի նախասիրությունների վրա, նույնպես ներառվել են շրջանակի տակ: Ցանցում տեղեկատվության հասանելիությունը հնարավորինս սահմանափակելու համար երկիրն ունի «Ոսկե վահան», որը զտում է ինտերնետ տրաֆիկը օրենքներին համապատասխան:
2019 թվականից ի վեր Չինաստանը սկսել է հրաժարվել արտասահմանյան համակարգիչներից և ծրագրերից։ 2020 թվականից չինական ընկերություններից պահանջվում է անցնել ամպային հաշվիչների, ինչպես նաև տրամադրել մանրամասն հաշվետվություններ ազգային անվտանգության վրա ՏՏ սարքավորումների ազդեցության մասին: Այս ամենը Միացյալ Նահանգների հետ առևտրային պատերազմի ֆոնին, որը կասկածի տակ է դրել չինացի մատակարարների կողմից 5G սարքավորումների անվտանգությունը:
Նման քաղաքականությունը համաշխարհային հանրության մոտ մերժում է առաջացնում։ Հետաքննությունների դաշնային բյուրոն ասել է, որ չինական սերվերների միջոցով տվյալների փոխանցումն անվտանգ չէ. դրանք կարող են հասանելի լինել տեղական հետախուզական գործակալությունների կողմից: Նրանից հետո մտահոգություն հայտնեցին միջազգային կորպորացիաները, այդ թվում՝ Apple-ը։
Համաշխարհային իրավապաշտպան Human Rights Watch կազմակերպությունը նշում է, որ Չինաստանը ստեղծել է «ամբողջական պետական էլեկտրոնային հսկողության ցանց և ինտերնետի գրաքննության բարդ համակարգ»։ Դրանց հետ համաձայն են ՄԱԿ-ի 25 անդամ երկրներ։
Ամենավառ օրինակը Սինցզյանն է, որտեղ պետությունը վերահսկում է 13 միլիոն ույղուրներին՝ ազգային մահմեդական փոքրամասնությանը: Օգտագործվում է դեմքի ճանաչում, բոլոր շարժումների, խոսակցությունների, նամակագրության և ռեպրեսիաների հետևում: Քննադատվում է նաև «սոցիալական կրեդիտ» համակարգը, երբ տարբեր ծառայություններից և նույնիսկ արտասահման թռիչքներից օգտվելու հնարավորություն ունեն միայն նրանց, ովքեր ունեն բավարար վստահելիության վարկանիշ՝ քաղաքացիական ծառայությունների տեսանկյունից։
Կան այլ օրինակներ. երբ պետությունները համաձայնում են միասնական կանոնների շուրջ, որոնք պետք է հնարավորինս պաշտպանեն անձնական ազատությունները և մրցակցությունը: Բայց այստեղ, ինչպես ասում են, կան նրբերանգներ։
Ինչպես է եվրոպական GDPR-ը փոխել աշխարհի տվյալների հավաքագրման և պահպանման եղանակը
2018 թվականից Եվրամիությունն ընդունել է GDPR՝ Տվյալների պաշտպանության ընդհանուր կանոնակարգը: Այն կարգավորում է այն ամենը, ինչ կապված է առցանց օգտատերերի տվյալների հավաքագրման, պահպանման և օգտագործման հետ: Երբ օրենքն ուժի մեջ մտավ մեկ տարի առաջ, այն համարվում էր աշխարհի ամենախիստ համակարգը՝ մարդկանց առցանց գաղտնիությունը պաշտպանելու համար:
Օրենքը թվարկում է համացանցի օգտատերերի տվյալների հավաքագրման և մշակման վեց իրավական հիմքեր. օրինակ՝ անձնական համաձայնություն, իրավական պարտավորություններ և կենսական շահեր: Կան նաև ութ հիմնական իրավունքներ ինտերնետ ծառայությունների յուրաքանչյուր օգտագործողի համար, ներառյալ տվյալների հավաքագրման մասին տեղեկանալու, ձեր մասին տվյալները ուղղելու կամ ջնջելու իրավունքը:
Ընկերություններից պահանջվում է հավաքել և պահպանել ծառայությունների մատուցման համար անհրաժեշտ տվյալների նվազագույն քանակությունը: Օրինակ, առցանց խանութը պարտադիր չէ, որ ձեզ հարցնի ձեր քաղաքական կարծիքների մասին՝ ապրանքը մատակարարելու համար:
Բոլոր անձնական տվյալները պետք է ապահով կերպով պաշտպանված լինեն օրենքի չափանիշներին համապատասխան՝ գործունեության յուրաքանչյուր տեսակի համար: Ավելին, անձնական տվյալներն այստեղ նշանակում են, ի թիվս այլ բաների, գտնվելու վայրի մասին տեղեկություն, էթնիկ պատկանելություն, կրոնական համոզմունքներ, դիտարկիչի թխուկներ:
Մեկ այլ բարդ պահանջ է տվյալների տեղափոխելիությունը մի ծառայությունից մյուսը. օրինակ, Facebook-ը կարող է ձեր լուսանկարները փոխանցել Google Photos: Ոչ բոլոր ընկերությունները կարող են իրենց թույլ տալ այս տարբերակը:
Չնայած GDPR-ն ընդունվել է Եվրոպայում, այն վերաբերում է բոլոր ընկերություններին, որոնք գործում են ԵՄ-ի շրջանակներում: GDPR-ը վերաբերում է բոլորին, ովքեր մշակում են ԵՄ քաղաքացիների կամ ռեզիդենտների անձնական տվյալները կամ ապրանքներ կամ ծառայություններ են առաջարկում նրանց:
Ստեղծվել է ՏՏ ոլորտի համար պաշտպանելու համար օրենքը վերածվել է ամենատհաճ հետևանքների։ Միայն առաջին տարում Եվրահանձնաժողովը տուգանել է ավելի քան 90 ընկերությունների՝ ավելի քան 56 միլիոն եվրո ընդհանուր գումարով: Ընդ որում, առավելագույն տուգանքը կարող է հասնել մինչև 20 միլիոն եվրոյի։
Շատ կորպորացիաներ բախվել են սահմանափակումների, որոնք լուրջ խոչընդոտներ են ստեղծել Եվրոպայում նրանց զարգացման համար։ Նրանց թվում էր Facebook-ը, ինչպես նաև British Airways-ը և Marriott հյուրանոցների ցանցը։ Բայց օրենքը առաջին հերթին հարվածեց փոքր ու միջին բիզնեսին. նրանք պետք է իրենց բոլոր ապրանքներն ու ներքին գործընթացները հարմարեցնեն իր նորմերին։
GDPR-ն ստեղծել է մի ամբողջ ոլորտ՝ իրավաբանական ընկերություններ և խորհրդատվական ընկերություններ, որոնք օգնում են ծրագրային ապահովման և առցանց ծառայությունները համապատասխանեցնել օրենքին: Նրա անալոգները սկսեցին հայտնվել այլ տարածաշրջաններում՝ Հարավային Կորեա, Ճապոնիա, Աֆրիկայում, Լատինական Ամերիկայում, Ավստրալիայում, Նոր Զելանդիայում և Կանադայում: Փաստաթուղթը մեծ ազդեցություն է ունեցել այս ոլորտում ԱՄՆ-ի, մեր երկրի և Չինաստանի օրենսդրության վրա։
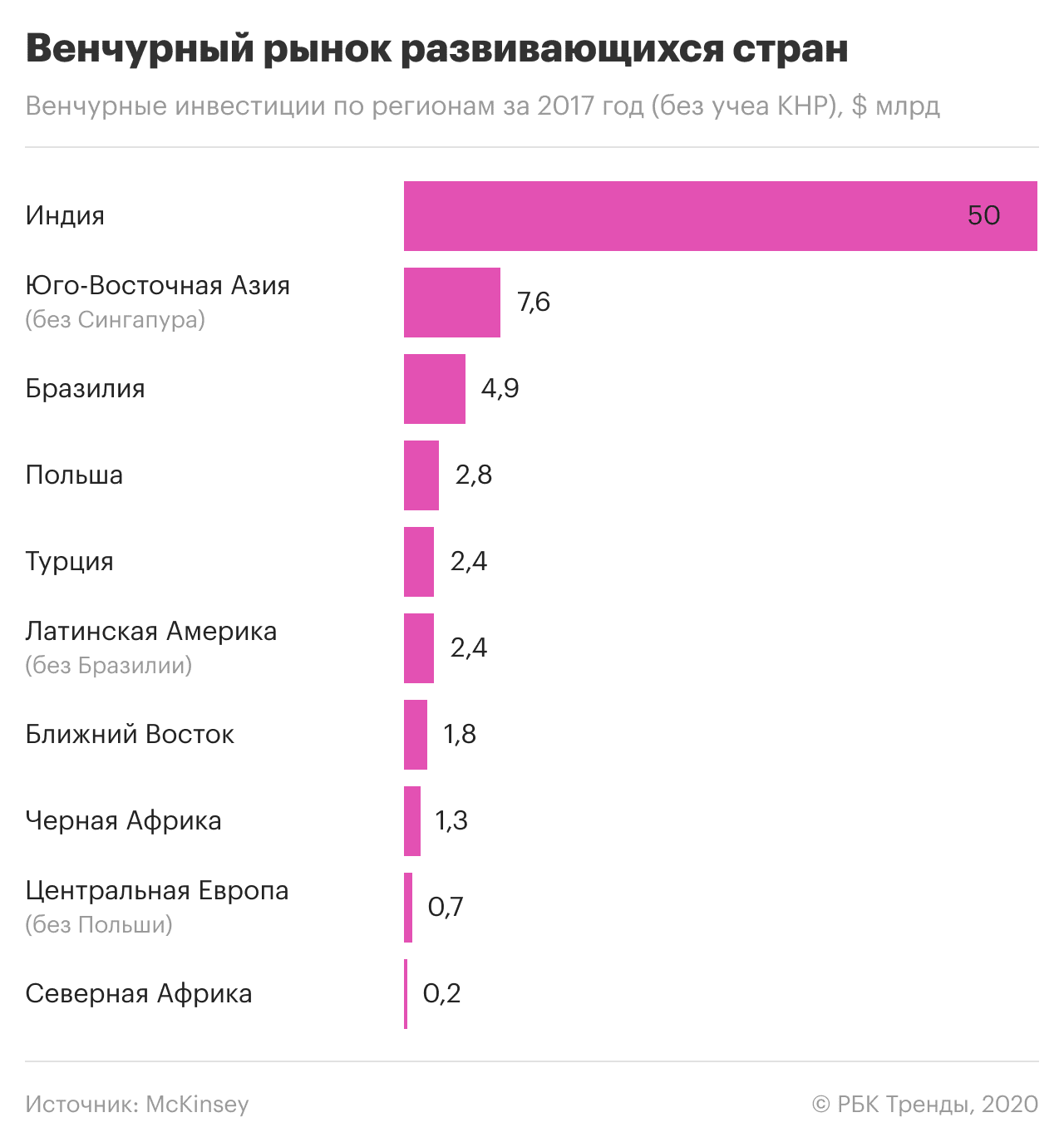
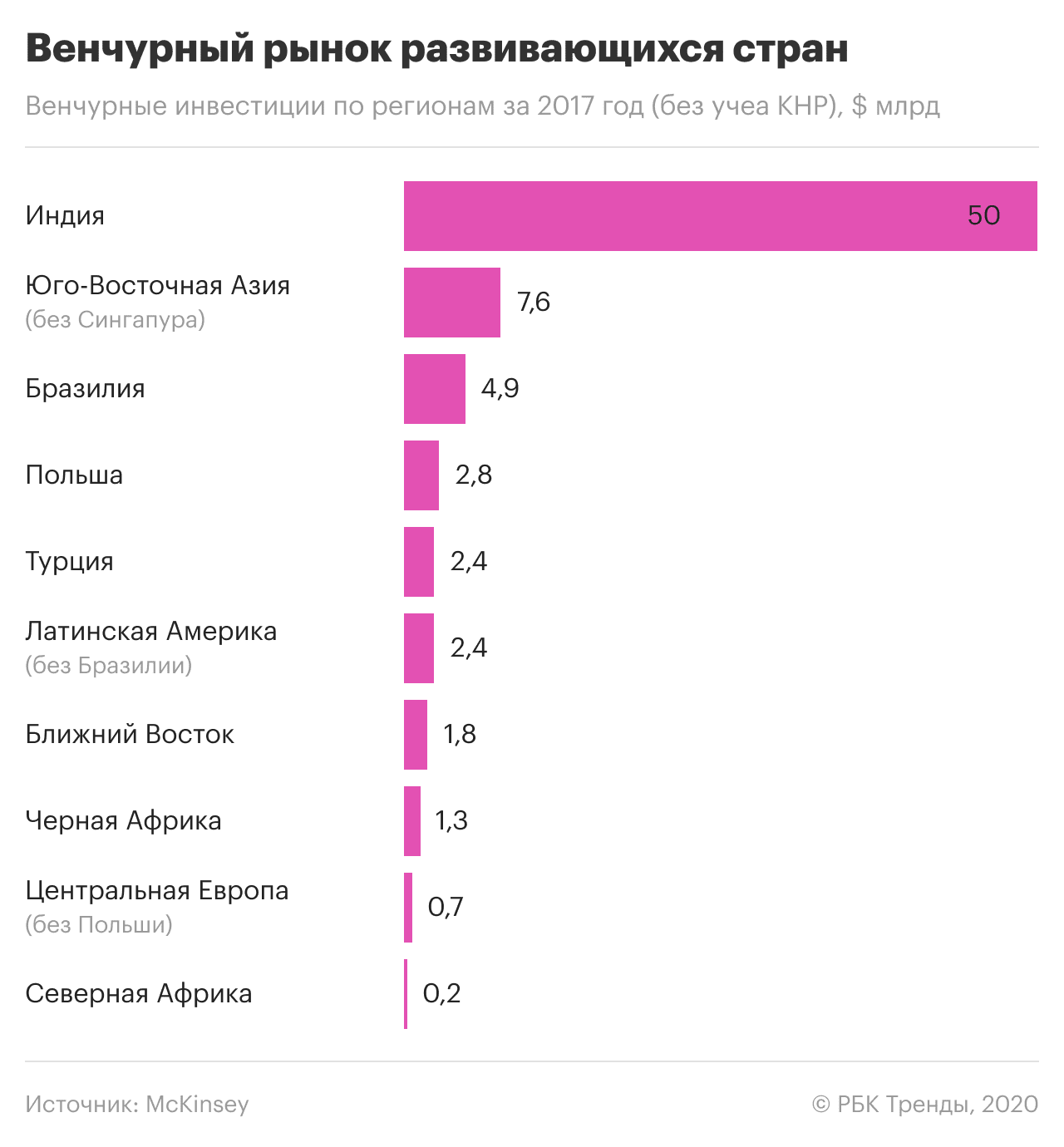
Կարելի է տպավորություն ստեղծվել, որ մեծ տվյալների և արհեստական ինտելեկտի ոլորտում տեխնոլոգիաների կիրառման և պաշտպանության միջազգային պրակտիկան բաղկացած է ծայրահեղություններից՝ ամբողջական հսկողություն կամ ճնշում ՏՏ ընկերությունների վրա, անձնական տեղեկատվության անձեռնմխելիություն կամ լիակատար անպաշտպանություն պետության և կորպորացիաների առաջ։ Ճիշտ չէ. կան նաև լավ օրինակներ:
AI և մեծ տվյալներ Ինտերպոլի ծառայության մեջ
Քրեական ոստիկանության միջազգային կազմակերպությունը՝ կարճ ասած՝ Ինտերպոլը, ամենաազդեցիկներից մեկն է աշխարհում: Այն ներառում է 192 երկիր։ Կազմակերպության հիմնական խնդիրներից է տվյալների բազաների կազմումը, որոնք օգնում են ամբողջ աշխարհի իրավապահ մարմիններին կանխարգելել և հետաքննել հանցագործությունը:
Ինտերպոլն իր տրամադրության տակ ունի 18 միջազգային բազա՝ ահաբեկիչների, վտանգավոր հանցագործների, զենքի, գողացված արվեստի գործերի և փաստաթղթերի մասին։ Այս տվյալները հավաքվում են միլիոնավոր տարբեր աղբյուրներից: Օրինակ՝ Dial-Doc գլոբալ թվային գրադարանը թույլ է տալիս բացահայտել գողացված փաստաթղթերը, իսկ Edison համակարգը՝ կեղծ:
Հանցագործների և կասկածյալների շարժումներին հետևելու համար օգտագործվում է դեմքի ճանաչման առաջադեմ համակարգ: Այն ինտեգրված է տվյալների բազաների հետ, որոնք պահում են լուսանկարներ և այլ անձնական տվյալներ ավելի քան 160 երկրներից: Այն լրացվում է հատուկ կենսաչափական հավելվածով, որը համեմատում է դեմքի ձևերն ու համամասնությունները, որպեսզի համապատասխանությունը հնարավորինս ճշգրիտ լինի:
Ճանաչման համակարգը հայտնաբերում է նաև այլ գործոններ, որոնք փոխում են դեմքը և դժվարացնում այն ճանաչելը. լուսավորություն, ծերություն, դիմահարդարում և դիմահարդարում, պլաստիկ վիրահատություն, ալկոհոլիզմի և թմրամոլության հետևանքները: Սխալներից խուսափելու համար համակարգի որոնման արդյունքները ստուգվում են ձեռքով:
Համակարգը ներդրվել է 2016 թվականին, և այժմ Ինտերպոլն ակտիվորեն աշխատում է այն բարելավելու ուղղությամբ։ Միջազգային նույնականացման սիմպոզիումն անցկացվում է երկու տարին մեկ անգամ, իսկ Face Expert աշխատանքային խումբը տարին երկու անգամ փորձի փոխանակում է կատարում երկրների միջև: Մեկ այլ խոստումնալից զարգացում ձայնի ճանաչման համակարգն է:
ՄԱԿ-ի միջազգային հետազոտական ինստիտուտը (UNICRI) և Արհեստական ինտելեկտի և ռոբոտաշինության կենտրոնը պատասխանատու են միջազգային անվտանգության ոլորտում նորագույն տեխնոլոգիաների համար: Սինգապուրը ստեղծել է Ինտերպոլի խոշորագույն միջազգային ինովացիոն կենտրոնը։ Նրա զարգացումների թվում են ոստիկանական ռոբոտը, որն օգնում է մարդկանց փողոցում, ինչպես նաև արհեստական ինտելեկտը և մեծ տվյալների տեխնոլոգիաները, որոնք օգնում են կանխատեսել և կանխել հանցագործությունը:
Այլապես ինչպես են մեծ տվյալները օգտագործվում պետական ծառայություններում.
NADRA (Պակիստան) – քաղաքացիների բազմակենսաչափական տվյալների բազա, որն օգտագործվում է արդյունավետ սոցիալական աջակցության, հարկային և սահմանային հսկողության համար:
ԱՄՆ-ի Սոցիալական ապահովության վարչությունը (SSA) օգտագործում է մեծ տվյալներ՝ հաշմանդամության վերաբերյալ հայցերն ավելի ճշգրիտ մշակելու և խարդախների թիվը կրճատելու համար:
ԱՄՆ կրթության նախարարությունը օգտագործում է տեքստի ճանաչման համակարգեր՝ կարգավորող փաստաթղթերը մշակելու և դրանցում կատարված փոփոխություններին հետևելու համար:
FluView-ը գրիպի համաճարակներին հետևելու և վերահսկելու ամերիկյան համակարգ է:
Իրականում մեծ տվյալները և արհեստական ինտելեկտը մեզ օգնում են շատ ոլորտներում: Դրանք կառուցված են առցանց ծառայությունների վրա, ինչպիսիք են դրանք, որոնք ձեզ տեղեկացնում են խցանումների կամ կուտակումների մասին: Բժշկության մեջ մեծ տվյալների և արհեստական ինտելեկտի օգնությամբ նրանք հետազոտություններ են անցկացնում, ստեղծում դեղեր և բուժման արձանագրություններ։ Նրանք օգնում են կազմակերպել քաղաքային միջավայրն ու տրանսպորտը, որպեսզի բոլորը հարմարավետ լինեն։ Ազգային մասշտաբով դրանք օգնում են զարգացնել տնտեսությունը, սոցիալական նախագծերը և տեխնիկական նորարարությունները։
Այդ իսկ պատճառով այդքան կարևոր է այն հարցը, թե ինչպես են հավաքվում և կիրառվում մեծ տվյալները, ինչպես նաև դրանց հետ աշխատող AI-ի ալգորիթմները: Միևնույն ժամանակ, այս ոլորտը կարգավորող կարևորագույն միջազգային փաստաթղթերն ընդունվել են բոլորովին վերջերս՝ 2018-19թթ. Անվտանգության համար մեծ տվյալների օգտագործման հետ կապված հիմնական երկընտրանքի միանշանակ լուծում դեռևս չկա: Երբ, մի կողմից, բոլոր դատական որոշումների և քննչական գործողությունների թափանցիկությունը, իսկ մյուս կողմից՝ անձնական տվյալների և ցանկացած տեղեկատվության պաշտպանությունը, որը հրապարակվելու դեպքում կարող է վնասել մարդուն։ Ուստի յուրաքանչյուր պետություն (կամ պետությունների միություն) ինքն է որոշում այս հարցը յուրովի։ Եվ այս ընտրությունը, հաճախ, որոշում է առաջիկա տասնամյակների ողջ քաղաքականությունն ու տնտեսությունը։
Բաժանորդագրվեք Trends Telegram ալիքին և տեղեկացեք ընթացիկ միտումներին և կանխատեսումներին տեխնոլոգիայի, տնտեսագիտության, կրթության և նորարարության ապագայի վերաբերյալ: